BLOG
Introducing NollaMD - a New SOTA for Differential Diagnosis in Visual Medicine
Introducing NollaMD - a New SOTA for Differential Diagnosis in Visual Medicine
9th April, 2026
9th April, 2026
7 min read
7 min read
Logan Grasby
Logan Grasby
Mason Pierce
Mason Pierce
Jackson Stokes
Jackson Stokes
Sean Geiger
Sean Geiger
Luis Soenksen
Luis Soenksen


TL;DR; We trained a custom reasoning model (NollaMD) for Nolla Health on a subset of their ~2M-image visual medicine dataset. Standard SFT and DPO both caused regressions in image understanding. GRPO over multiple-choice questions worked: with no reasoning traces in the training data, the model learned to reason its way to the right diagnosis on its own. The result beats frontier models on visual medicine accuracy at roughly 1/30th the cost and the gains showed up qualitatively in ways our benchmarks couldn't fully capture.
For Nolla, a specialist model trained on expert clinical data delivers frontier-level diagnostic accuracy at a fraction of the cost, helping pave the way for accessible, AI-powered healthcare.
TL;DR; We trained a custom reasoning model (NollaMD) for Nolla Health on a subset of their ~2M-image visual medicine dataset. Standard SFT and DPO both caused regressions in image understanding. GRPO over multiple-choice questions worked: with no reasoning traces in the training data, the model learned to reason its way to the right diagnosis on its own. The result beats frontier models on visual medicine accuracy at roughly 1/30th the cost and the gains showed up qualitatively in ways our benchmarks couldn't fully capture.
For Nolla, a specialist model trained on expert clinical data delivers frontier-level diagnostic accuracy at a fraction of the cost, helping pave the way for accessible, AI-powered healthcare.
Naming a condition is not the same as diagnosing one. When you go to see a clinician specialist (like a dermatologist), the critical first thing they do is visually observe the condition you came in about. We've had narrow models that have been able to do this for a very long time. Nolla Health, in fact, already has a state-of-the-art model for visually diagnosing acne and moles. The thing that these image classifiers fail to capture is the second step that a physician takes: asking you questions around why you might have this condition. Where have you been? What have you been exposed to? In a differential diagnosis (DDX), the idea is to have a set of candidate conditions, usually based on what you've seen, and progressively ask questions to narrow down that list until you come to a final answer or a final set of most likely conditions that you can then decide on a treatment plan for. That second step is where half of the diagnosis actually happens. And it's the step an image classifier, no matter how good, cannot do.
Naming a condition is not the same as diagnosing one. When you go to see a clinician specialist (like a dermatologist), the critical first thing they do is visually observe the condition you came in about. We've had narrow models that have been able to do this for a very long time. Nolla Health, in fact, already has a state-of-the-art model for visually diagnosing acne and moles. The thing that these image classifiers fail to capture is the second step that a physician takes: asking you questions around why you might have this condition. Where have you been? What have you been exposed to? In a differential diagnosis (DDX), the idea is to have a set of candidate conditions, usually based on what you've seen, and progressively ask questions to narrow down that list until you come to a final answer or a final set of most likely conditions that you can then decide on a treatment plan for. That second step is where half of the diagnosis actually happens. And it's the step an image classifier, no matter how good, cannot do.
That’s when we got involved. Nolla has an incredible dataset spanning ~2 million labeled visual medicine images across more than 3,000 unique conditions. Our goal is to make a reasoning model that could correctly reason over these visual conditions and then ask meaningful questions to narrow down the possible diseases like a clinician would. We chose Google’s MedGemma model as a base architecture for two reasons. First, the MedSigLip encoder is trained to be natively multimodal, rather than image tokens projected down to language space, and second, the focus on medical text and images limited the need for domain adaptive pre-training.
That’s when we got involved. Nolla has an incredible dataset spanning ~2 million labeled visual medicine images across more than 3,000 unique conditions. Our goal is to make a reasoning model that could correctly reason over these visual conditions and then ask meaningful questions to narrow down the possible diseases like a clinician would. We chose Google’s MedGemma model as a base architecture for two reasons. First, the MedSigLip encoder is trained to be natively multimodal, rather than image tokens projected down to language space, and second, the focus on medical text and images limited the need for domain adaptive pre-training.
A lot of work went into defining the experience of this model, including feedback from real board-certified doctors - that will be discussed in a second blog post.
A lot of work went into defining the experience of this model, including feedback from real board-certified doctors - that will be discussed in a second blog post.
We began with the obvious strategy of SFT (Supervised Fine-Tuning) on the labeled data. We were surprised to find that doing SFT with the ground truth labels made the model significantly less capable at understanding images and it was extremely prone to catastrophic forgetting. We considered building a data mixture but ended up deciding that the approach we needed to take had to be robust enough to be generally useful as the requirements for this model changed over time. We also tried DPO (Direct Preference Optimization) and still found that something about the addition of images caused the model to decide to disregard the image entirely. Every supervised method we tried ended up teaching the model to mimic outputs, not to reason. What we needed was a training signal that rewarded getting it right, not looking right, which meant some form of RL (Reinforcement Learning).
We began with the obvious strategy of SFT (Supervised Fine-Tuning) on the labeled data. We were surprised to find that doing SFT with the ground truth labels made the model significantly less capable at understanding images and it was extremely prone to catastrophic forgetting. We considered building a data mixture but ended up deciding that the approach we needed to take had to be robust enough to be generally useful as the requirements for this model changed over time. We also tried DPO (Direct Preference Optimization) and still found that something about the addition of images caused the model to decide to disregard the image entirely. Every supervised method we tried ended up teaching the model to mimic outputs, not to reason. What we needed was a training signal that rewarded getting it right, not looking right, which meant some form of RL (Reinforcement Learning).
But RL has a chicken-and-an-egg problem. The whole premise of policy optimization is that the model occasionally produces a good output, gets rewarded, and the gradient reinforces whatever it did to get there. The issue is with the combination of possible granularities of diseases and disease labels, as well as limitations in MedGemma's ability to identify these diseases. The chance of it randomly emitting the correct diagnosis was very close to zero, which we quickly learned meant that the model would never learn anything at all through this method.
But RL has a chicken-and-an-egg problem. The whole premise of policy optimization is that the model occasionally produces a good output, gets rewarded, and the gradient reinforces whatever it did to get there. The issue is with the combination of possible granularities of diseases and disease labels, as well as limitations in MedGemma's ability to identify these diseases. The chance of it randomly emitting the correct diagnosis was very close to zero, which we quickly learned meant that the model would never learn anything at all through this method.
The unlock was multiple choice with single-step GRPO (Group Relative Policy Optimization). Instead of asking the model to produce a diagnosis from nothing, we framed each training example as a multiple choice question over the image. The model was given an image and prompt to first think about the image, and then select the correct condition from one of six very visually similar options. Once the model was SOTA, we made the task more significantly difficult by giving it an initial user message with an image and making it create a list of diagnoses. We were pleasantly surprised to discover that the model not only got better at selecting the right diagnosis, but it also learned to reason in a very similar way to a clinician.
The unlock was multiple choice with single-step GRPO (Group Relative Policy Optimization). Instead of asking the model to produce a diagnosis from nothing, we framed each training example as a multiple choice question over the image. The model was given an image and prompt to first think about the image, and then select the correct condition from one of six very visually similar options. Once the model was SOTA, we made the task more significantly difficult by giving it an initial user message with an image and making it create a list of diagnoses. We were pleasantly surprised to discover that the model not only got better at selecting the right diagnosis, but it also learned to reason in a very similar way to a clinician.

Evals are notoriously hard, but we settled on three ways to validate the models’ performance:
A multiple-choice holdout set, similar to the train set.
Reading the reasoning traces: Looking for reward hacking, hallucinated image features, fake reasoning, etc. In a qualitative sense, comparing base MedGemma with the trained versions was night and day in terms of the quality of its reasoning and output
Evals are notoriously hard, but we settled on three ways to validate the models’ performance:
A multiple-choice holdout set, similar to the train set.
Reading the reasoning traces: Looking for reward hacking, hallucinated image features, fake reasoning, etc. In a qualitative sense, comparing base MedGemma with the trained versions was night and day in terms of the quality of its reasoning and output
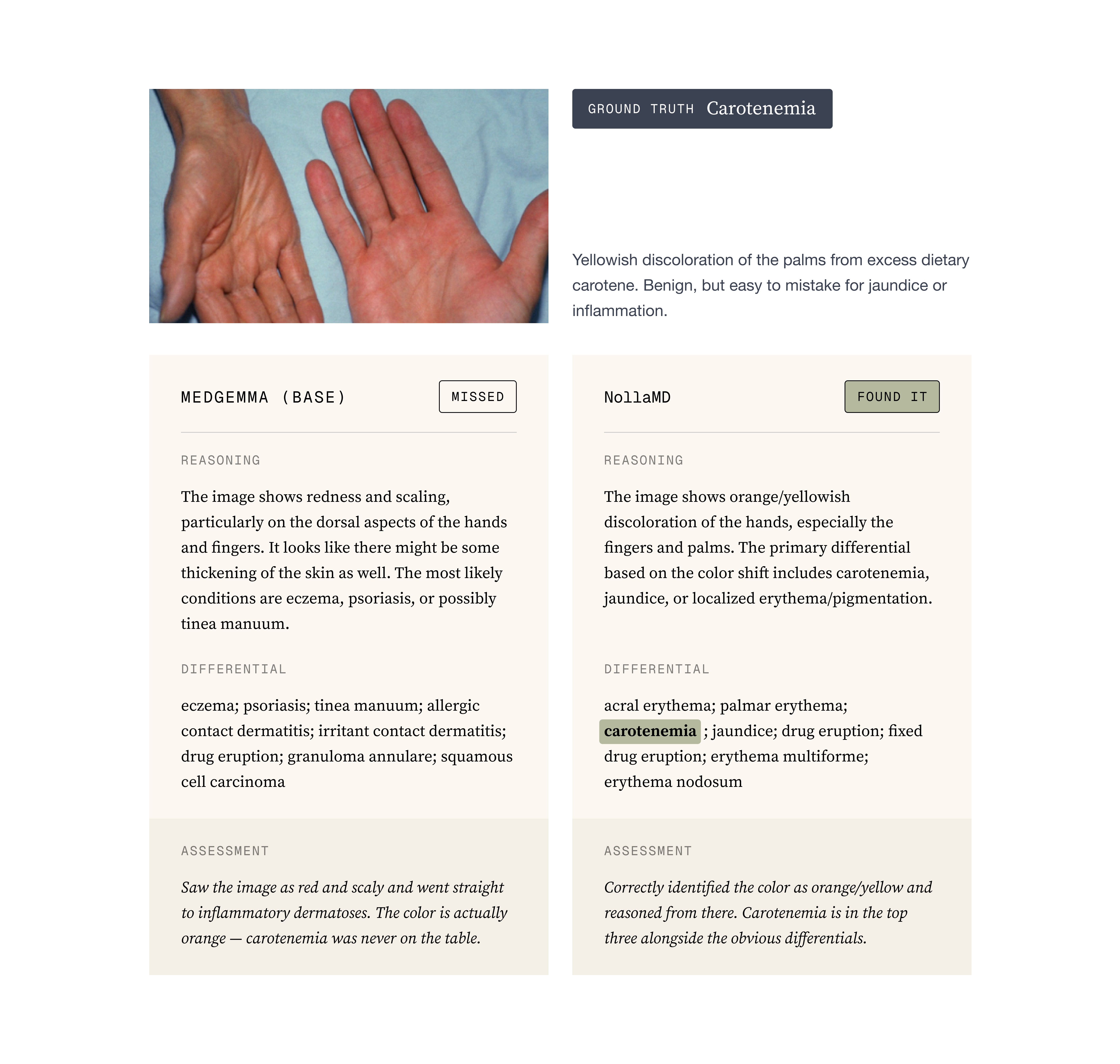
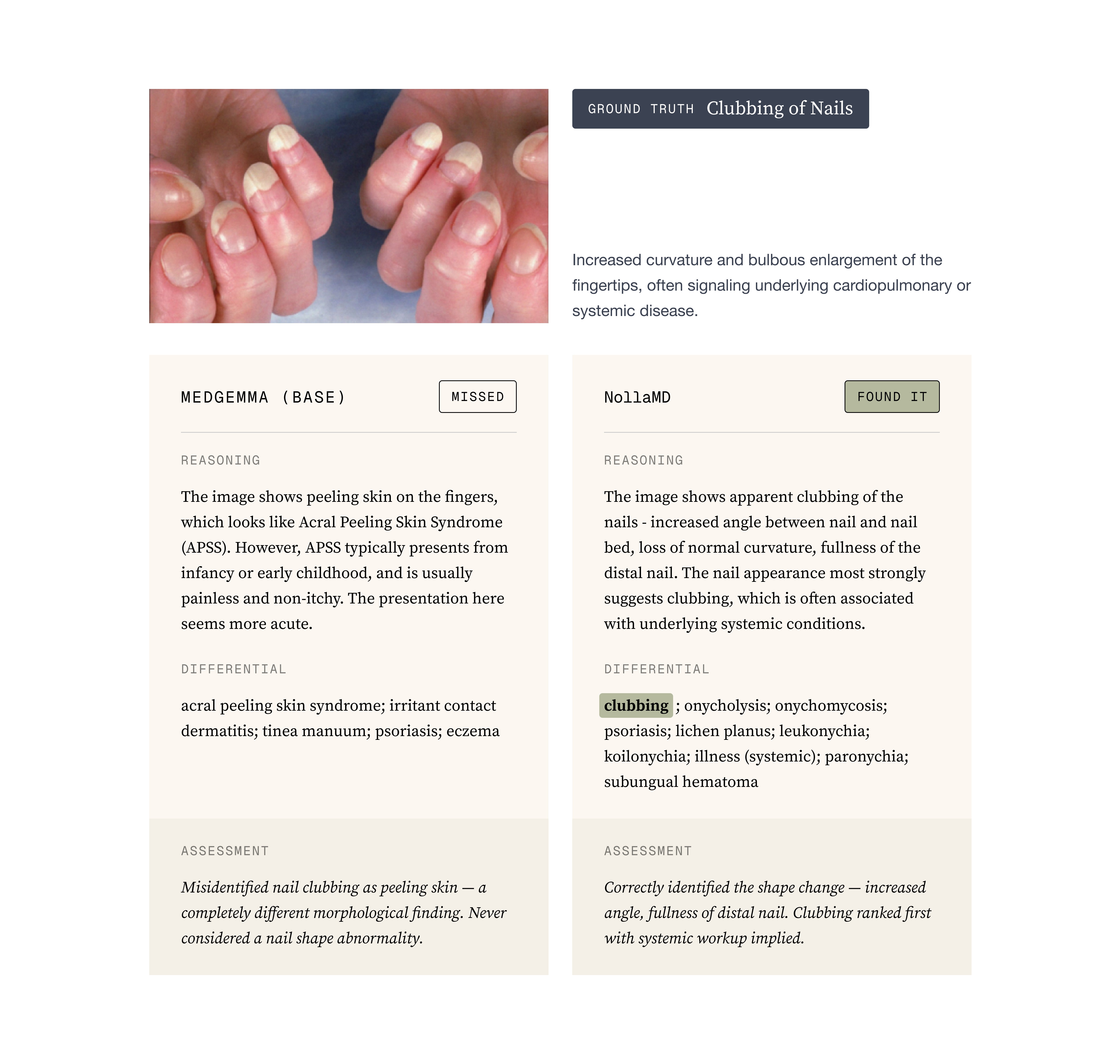
Attention Maps: An attention map is essentially a visualization of what the model is paying attention to. You can do this for both text and images but images are the easiest to understand. For us, the most telling thing that the model was learning was by comparing base MedGemma with our trained version and visualizing how the attention became more focused around the obvious site that a typical physician would observe.
Attention Maps: An attention map is essentially a visualization of what the model is paying attention to. You can do this for both text and images but images are the easiest to understand. For us, the most telling thing that the model was learning was by comparing base MedGemma with our trained version and visualizing how the attention became more focused around the obvious site that a typical physician would observe.
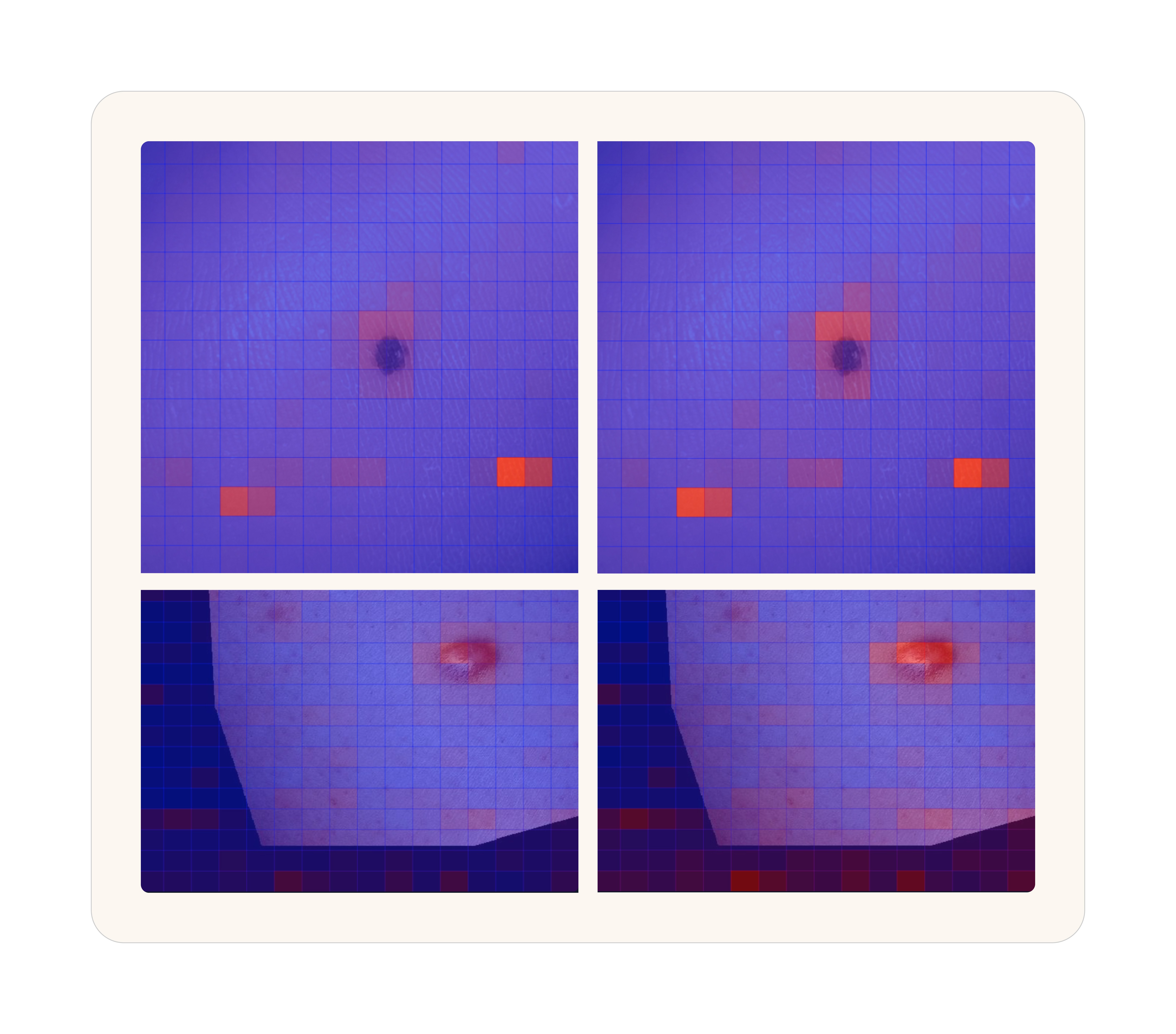
Attention heatmaps over the same image. Blue indicates low attention, red indicates high. Left: base MedGemma 27B. Right: NollaMD after fine-tuning. The trained model focuses sharply on the clinically relevant features.
To the point about evals being notoriously hard. One thing we don’t capture in our evals that we discovered after training when the Nolla team was using the model, is that because we have so many conditions and some of them are quite rare, NollaMD is dramatically better than state-of-the-art in those rare diseases but relatively average or even slightly worse in the common diseases. The value of a custom model shows up in the out of distribution content, not in the well-represented open internet data.
Attention heatmaps over the same image. Blue indicates low attention, red indicates high. Left: base MedGemma 27B. Right: NollaMD after fine-tuning. The trained model focuses sharply on the clinically relevant features.
To the point about evals being notoriously hard. One thing we don’t capture in our evals that we discovered after training when the Nolla team was using the model, is that because we have so many conditions and some of them are quite rare, NollaMD is dramatically better than state-of-the-art in those rare diseases but relatively average or even slightly worse in the common diseases. The value of a custom model shows up in the out of distribution content, not in the well-represented open internet data.
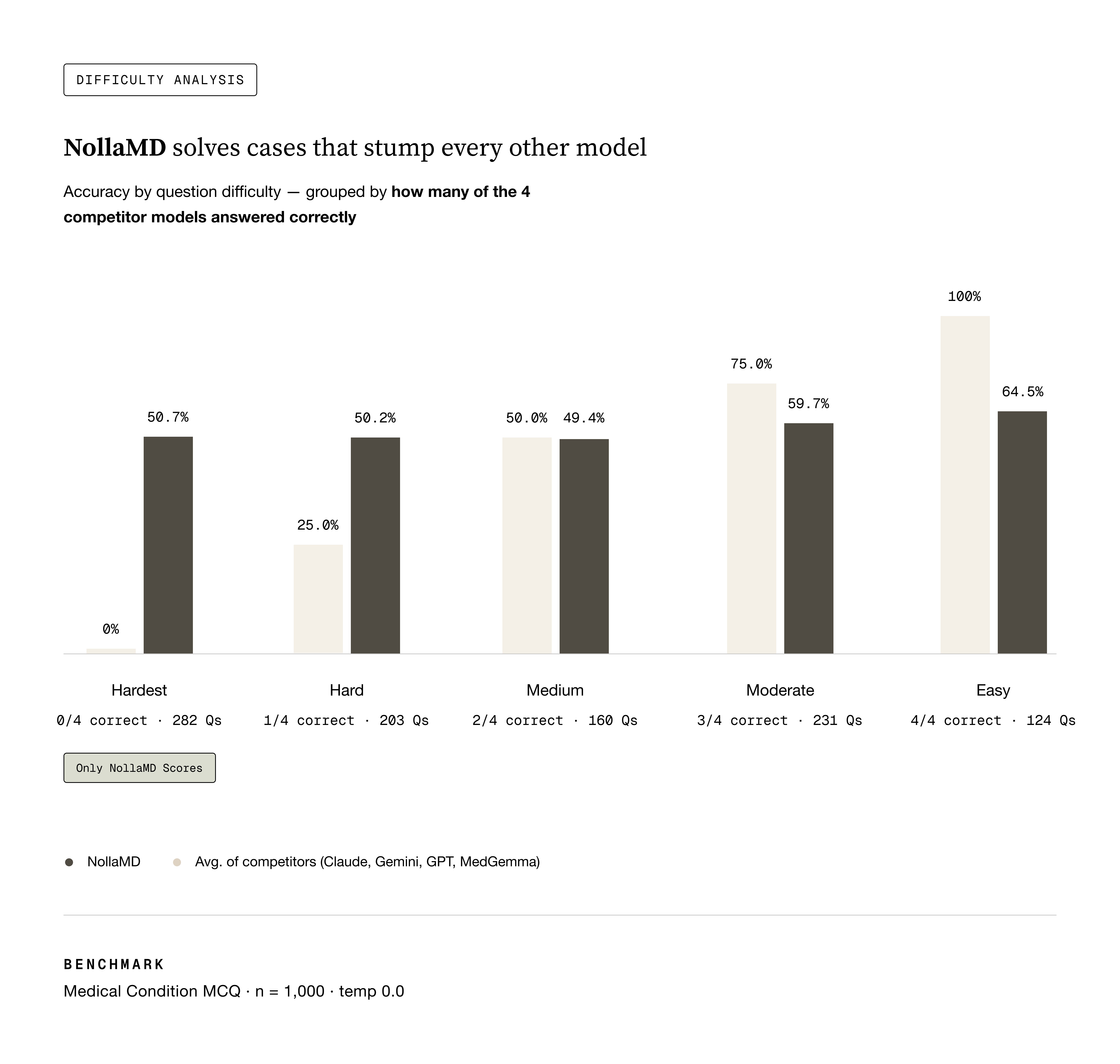
One interesting thing that we discovered was that training on this very simple task generalized to a much better model in many ways that are almost impossible to evaluate accurately. The best eval for that metric is probably this one:
One interesting thing that we discovered was that training on this very simple task generalized to a much better model in many ways that are almost impossible to evaluate accurately. The best eval for that metric is probably this one:
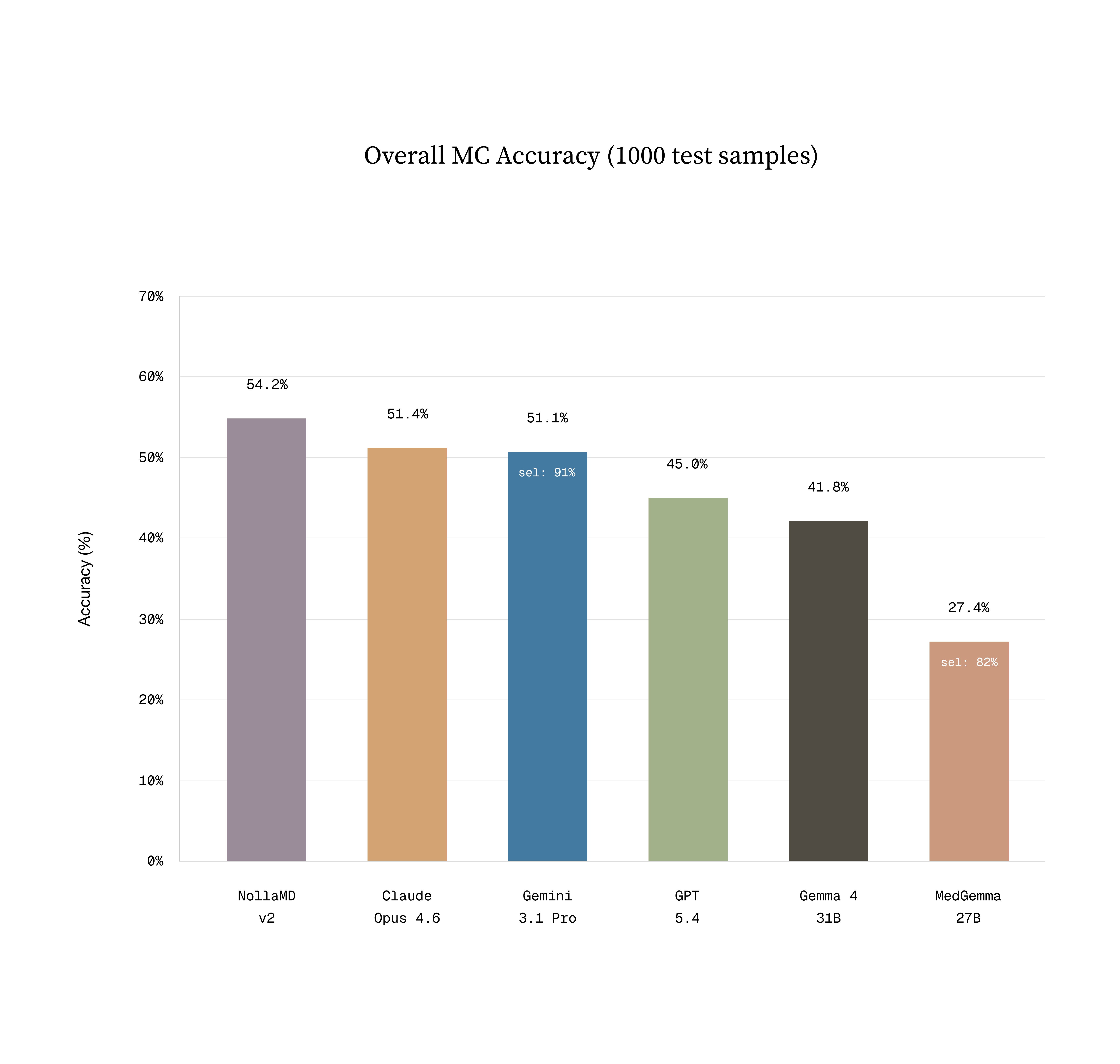
Sean's vibes actually matched what we measured. NollaMD is state-of-the-art in visual medicine on our holdout test set at a fraction of the cost of frontier models.
Sean's vibes actually matched what we measured. NollaMD is state-of-the-art in visual medicine on our holdout test set at a fraction of the cost of frontier models.
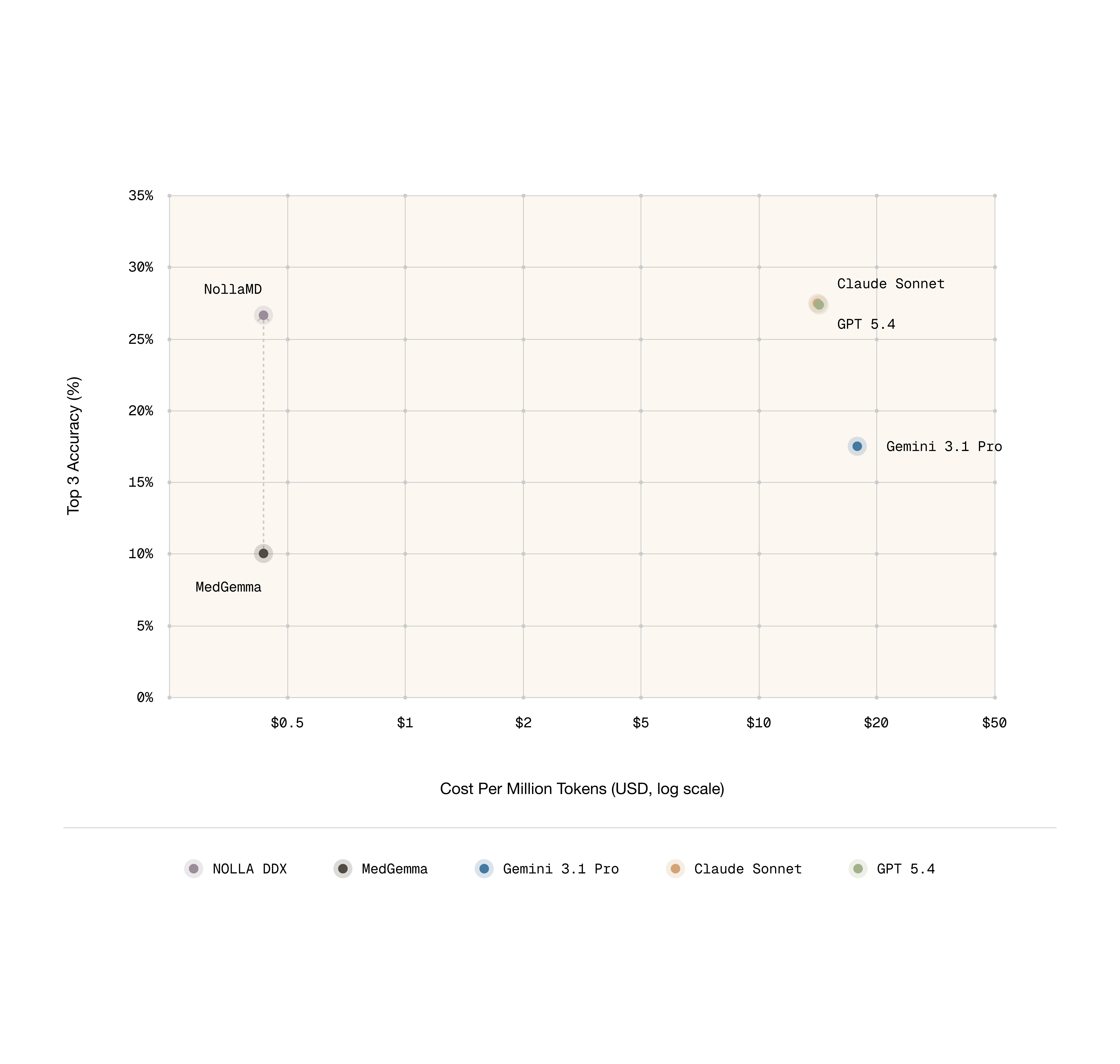
Thankfully, it’s true that having models ask questions about the condition frequently leads to a more accurate diagnosis. Interestingly, despite not being trained on this directly, DDX performance through conversation notably improved. The best performing closed source model is gpt-5.4 and NollaMD is on par with its performance here.
Thankfully, it’s true that having models ask questions about the condition frequently leads to a more accurate diagnosis. Interestingly, despite not being trained on this directly, DDX performance through conversation notably improved. The best performing closed source model is gpt-5.4 and NollaMD is on par with its performance here.
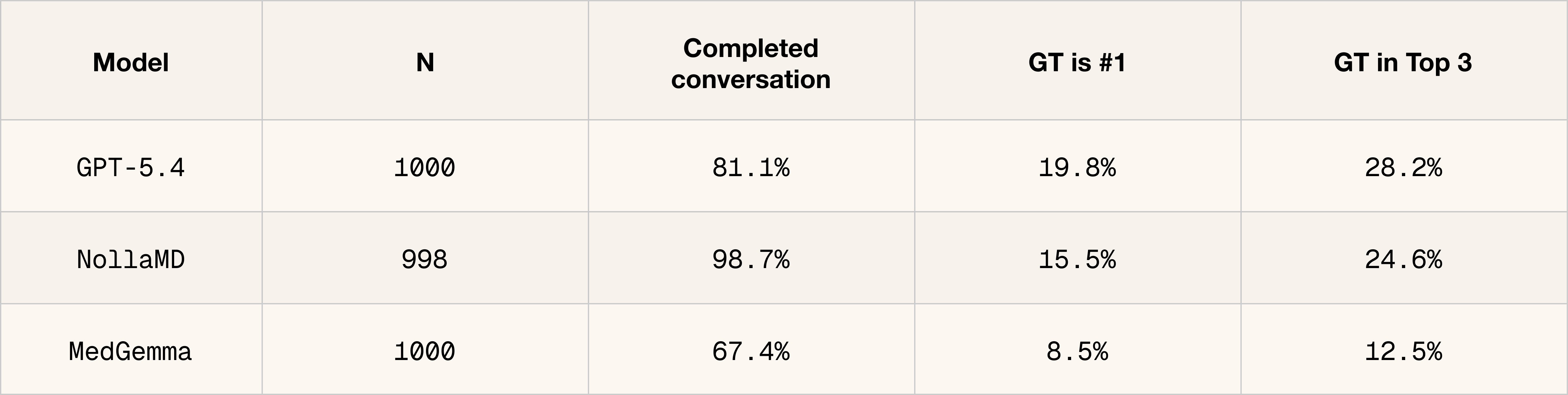
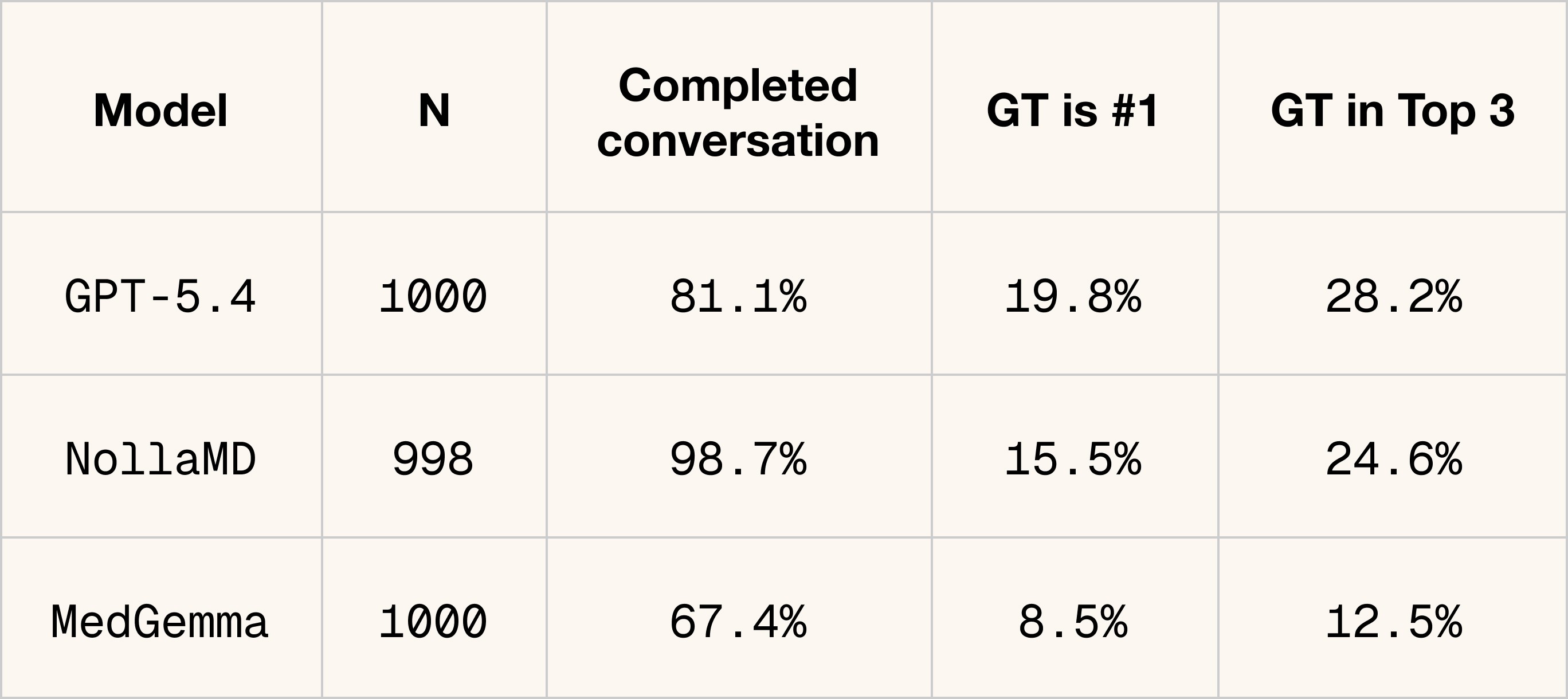
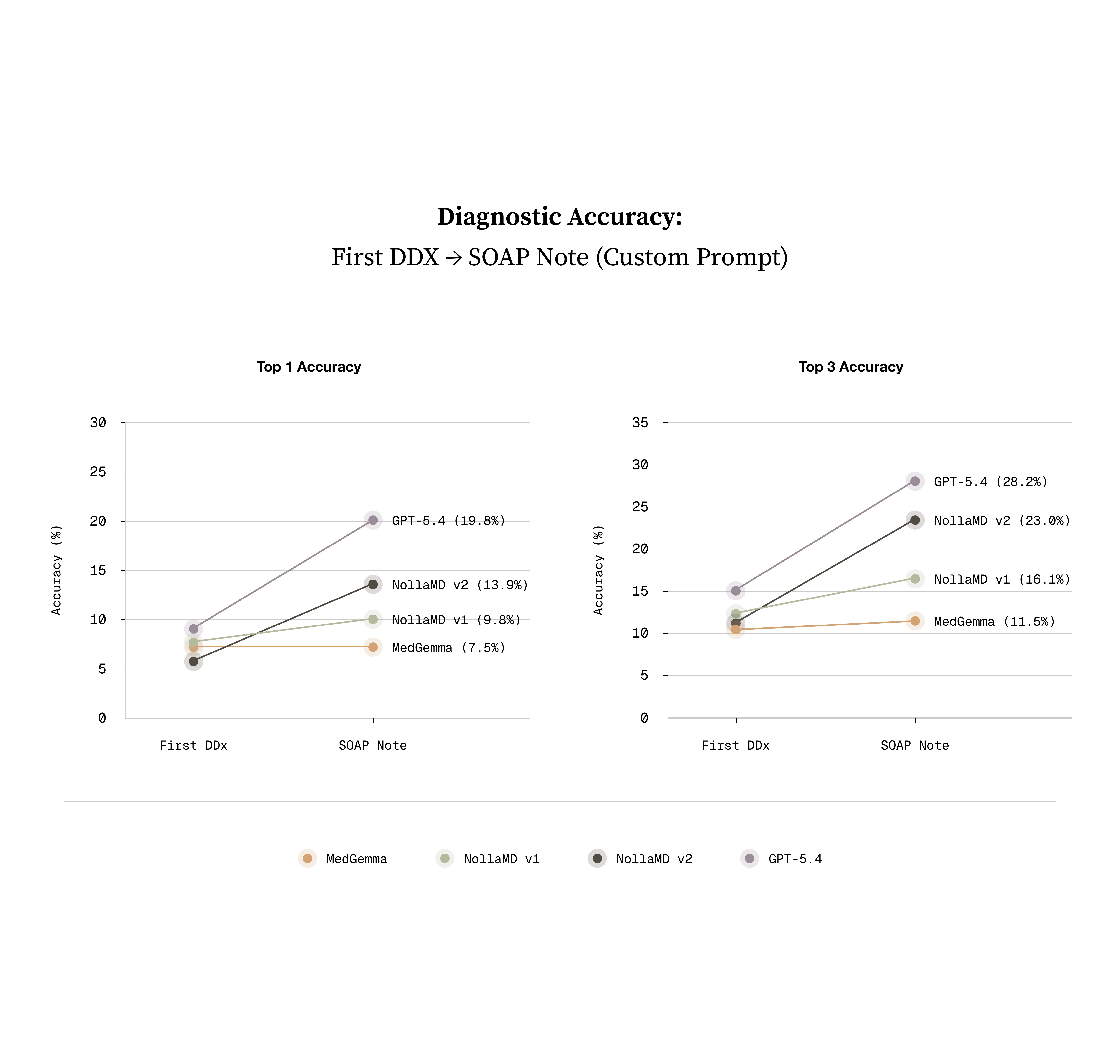
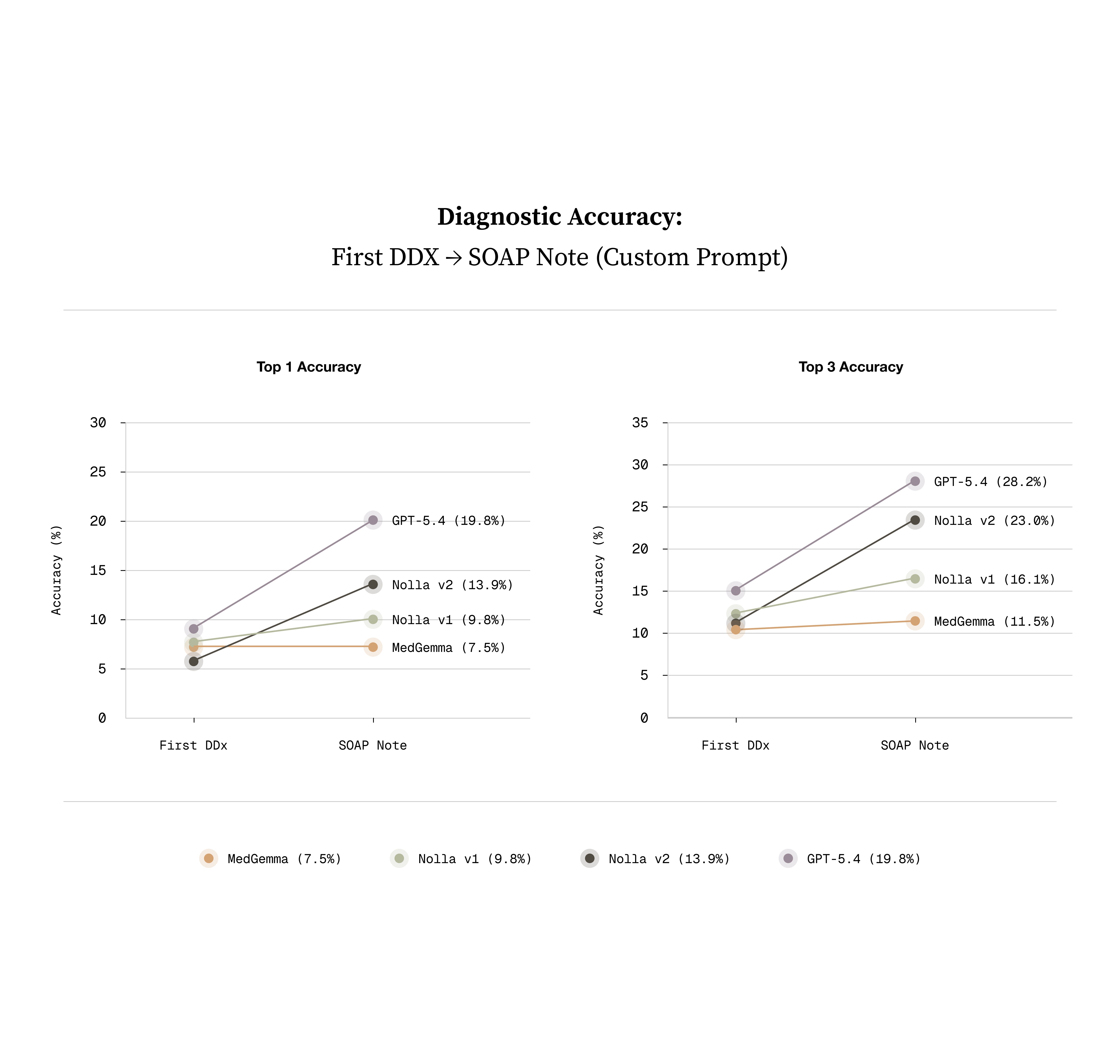
What we've shipped is the visual part of a clinician's diagnostic process. It's step one. The next phase is teaching the model to go after the context it doesn't have yet, asking follow-up questions and driving the conversation toward a diagnosis and treatment plan.
What we've shipped is the visual part of a clinician's diagnostic process. It's step one. The next phase is teaching the model to go after the context it doesn't have yet, asking follow-up questions and driving the conversation toward a diagnosis and treatment plan.
We're excited about OAPL (Optimal Advantage-based Policy Optimization with a Lagged Inference Policy) from Databricks for that next phase. In our early testing it consistently outperforms GRPO, and it opens up a new training UX where we can confirm rewards before actually taking a step. More on that soon.
We're excited about OAPL (Optimal Advantage-based Policy Optimization with a Lagged Inference Policy) from Databricks for that next phase. In our early testing it consistently outperforms GRPO, and it opens up a new training UX where we can confirm rewards before actually taking a step. More on that soon.
Why this matters
Why this matters
On a specific task, a fine-tuned 27B model can beat the leading frontier models and this isn't unique to medicine. Any domain with verifiable outcomes and a well-scoped task is a candidate for the same approach. Frontier models are generalists; a fine-tuned model trades breadth for depth, runs at roughly 1/30th the cost, and learns to reason the way your experts reason instead of however the frontier model happens to feel that week. For the tasks that matter to your product, that trade is almost always worth making.
On a specific task, a fine-tuned 27B model can beat the leading frontier models and this isn't unique to medicine. Any domain with verifiable outcomes and a well-scoped task is a candidate for the same approach. Frontier models are generalists; a fine-tuned model trades breadth for depth, runs at roughly 1/30th the cost, and learns to reason the way your experts reason instead of however the frontier model happens to feel that week. For the tasks that matter to your product, that trade is almost always worth making.
If you're interested in building domain-specific models for your product, reach out to Trainloop. To learn more about Nolla's AI-powered medicine platform, visit Nolla Health.
If you're interested in building domain-specific models for your product, reach out to Trainloop. To learn more about Nolla's AI-powered medicine platform, visit Nolla Health.
Training reasoning models aligned with your goals.
Email: founders@trainloop.ai
LEGAL
© 2026 TrainLoop. All rights reserved.
North Beach, San Francisco, CA
Training reasoning models aligned with your goals.
Email: founders@trainloop.ai
LEGAL
© 2026 TrainLoop. All rights reserved.
North Beach, San Francisco, CA